

firefox29
-
Content Count
20 -
Joined
-
Last visited
Posts posted by firefox29
-
-
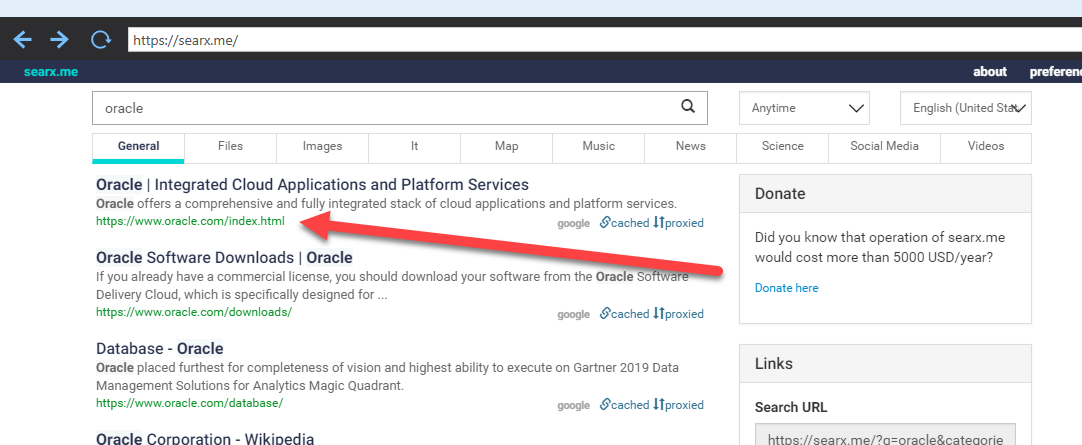
Hi I'm having trouble scraping the first URL returned per search on https://searx.me/.
Can someone please offer a tip or suggestion on how I can scrape the first URL that shows up after a search on searx.me?
Thank you,
-
Pash this worked brilliantly, thank you for your help. I greatly appreciate it.
And hope you have a wonderful day!

-
Thank you Pash, I greatly appreciate your help.
This worked, but as you can see from the screen capture below it took all of the listings down the page with the green link, not just the 1st link.
How would I just get the 1st link.
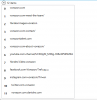
-
The current issue I need help with is when trying to use Scrape Attribute to get the first returned result.
In the screen shot below that would be the 1st loaded company which was Sony. I'm looking to get the sony.com.
I tried selecting it but keep getting a Offset, which when I run the next company can move and no longer works, how should I proceed?

Any help will be greatly appreciated,
Thank you for your time.
Larry
-
Thank you Pash this worked great!! We greatly appreciate your help.

-
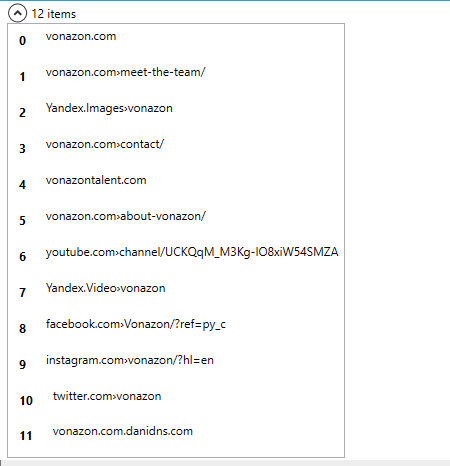
Hi we need a ubot experts help,
We would like to scrap the url's found within each company on this page.
here is the site:
See images below.
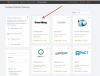
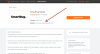
Any help will be greatly appreciated.
And if possible, if you could suggest a good site to get advance training for ubot we would be very grateful.
Thank you,
-
Helloinsomina,
We have another site we would like to do this too, we were wondering how you found the "Containers" <class=*mod-*> We've tried designating the scrape from all over the page and are unable to find the same starting point that's listed under your "Advanced Element editor:" Any help would be greatly appreciated, also is there any training sites you would suggest so that we can build our skills with Ubot?
Edit: seems I'm too slow today
 but I'll leave it here anyways.
but I'll leave it here anyways.You will need to add them to a list or table or something but this should get you pretty far:
navigate("http://launchpoint.marketo.com/?show=all","Wait") wait for browser event("Everything Loaded","") wait for element(<id="logo-footer">,"","Appear") wait(2) clear list(%containers) add list to list(%containers,$scrape attribute(<class=w"*mod-*">,"innerhtml"),"Don\'t Delete","Global") loop($list total(%containers)) { set(#url,$find regular expression($next list item(%containers),"(?<=href=\\\").*?(?=\\\")"),"Global") navigate(#url,"Wait") set(#website,$scrape attribute(<class="WebsiteURL">,"fullhref"),"Global") } -
Thank you CD & HelloInsomia,
We greatly appreciate your help.
-
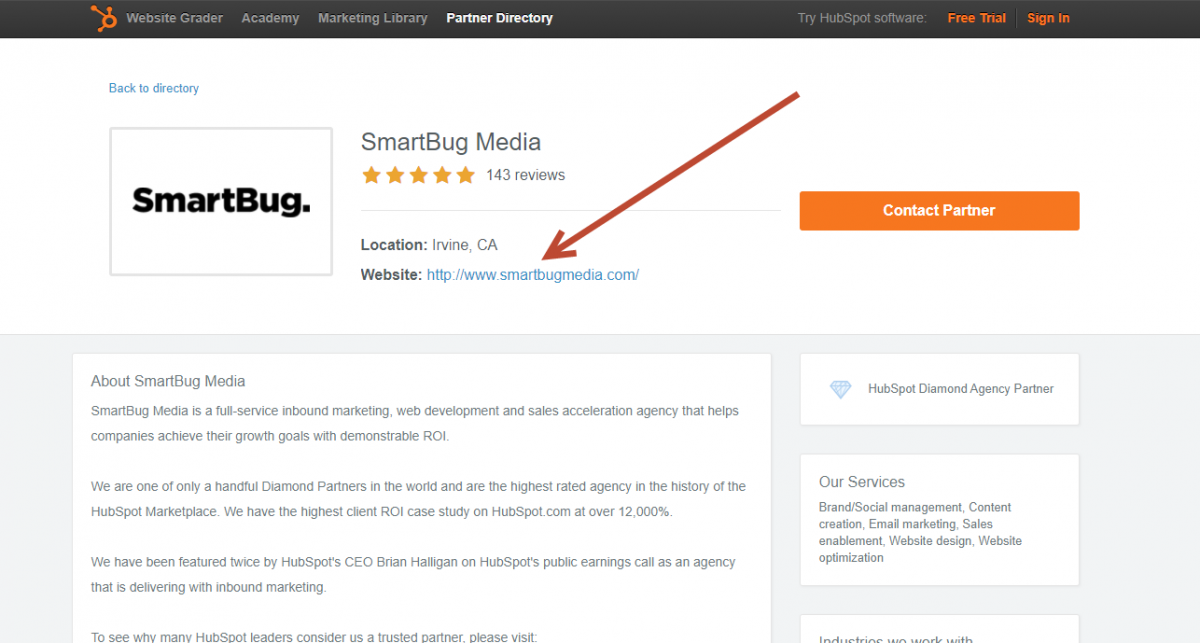
We need your help expert ubot users.
We would like to scrape the urls from all the 821 companies show on this site below.
http://launchpoint.marketo.com/?show=all
Seen in the screen shots it requires to click on the company, scroll a bit down and off to the right is the "Website" which if clicked takes you to the company website.
What would be the best way to scrape all 821 companies websites of this page?
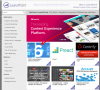
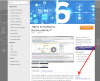
Thank you for any help we greatly appreciate your time.

-
try chrome 49
That is great thank you, it didn't fix the issue, so now I'm just trying to figure out why I can log into my own account with ubot but when we try our clients account it gives this "Stronger Security is Required" and says to disable TLS 1.0. Which I've done for browsers.
-
Hi Gogetta, I tried this but I still get the issue. I'm not sure what the issue could be.
Thank you again for your help I greatly appreciate it!!
-
Hi I've been trying to login to Salesforce using Ubot, and I'm getting this error "Stronger Security is required". For more information see Salesforce disabling TLS 1.0.
Here is the link they supplied: https://help.salesforce.com/articleView?id=000221207&type=1
I tried disabling the TLS 1.0 on my chrome browser but what you can see with the screen shots, even though I disabled it on my regular browser which is running Chrome 56, see screen shot below.
The ubot chrome is running 21.
Do I need to upgrade my browser on Ubot and if so how?
Or is there a different resolve, please advise any help will be greatly appreciated.
Thank you


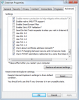
-
I'm unable to scrape a website table using "scrape a table" so I used "add list to list" with "scrape attribute".
I'm able to get the data I want this way but it list it like this:
Row: 0
Name
Address
Company
Row 1
Name
Address
Company
When I would like it to be in a table format like this:
Column 1: Name
Column 2: Address
Column 3: Company
So I can export it with the information listed across the excel page via Columns and not down the page in rows.
Any help will be greatly appreciated.
-
Jane thank you for the quick detailed response I really appreciate it, you rock!! Here is the error I got when trying to use the code on CMD.
Do you know what I should do to fix this? Because from what I can tell when I right click on my my documents properties it's read only. And when I unclick it apply then hit ok, when I go back to it it's still read only. But when I right click the Computer Icon, go to secuirty and then permissions it says I have FULL Control.
http://i7.photobucket.com/albums/y266/larrydalecarson/cmderror_zpsd05c2347.jpghttp://i7.photobucket.com/albums/y266/larrydalecarson/readonly_zps9e4a2f15.jpg
-
Hi I'm very new to Ubot Studio, I'm getting this error when I try to use your bot.http://i7.photobucket.com/albums/y266/larrydalecarson/error_zps0a9ad3b5.jpg
Any help will be greatly appreciated.
-
Hi I registered, and I'm interested in finding out how much in total it costs for the training for all videos, also I have the standard version of Ubot Studio, is it benificial to purchase the 300+ ubot source code bot? And why?
Please let me know as soon as possible I would like to purchase ASAP once I know what I get for what price.
Thank you,
-
Thank you so much Kreatus, we've received it. Will try it out, and post a review with in the next week.
You Rock!! Hope you have a great day!
-
Hi Kreatus thank you for the quick response, I emailed you from my yahoo email address this time with a copy of the receipt, and my boss's email address.
-
Hi Kreatus, we purchased the Youtubeblaster pro for $59 on 8/14/2013. Receipt # ****-****-****3928
We've been slammed with work and haven't had a chance to check it out.
I checked with my boss who purchased it and we've not received an email with the licence on it only the Paypal confirmation that we paid.
I've sent you an email today at support@custombotsolutions.com with a screen shot of the order and the receipt number.
Please send the licience number as soon as you can we would like to use this on our next project. We will post a review shortly after.
Thank you,









Issue with Ubot studio - screenshots shown.
in General Discussion
Posted
Hi can I get anyones help please?
")



These 3 errors below are what I see before it starts.
I have the latest version.
I saw in a different forum to install this java, I did.
https://www.java.com/download/manual.jsp
As well when I checked the X64 version it said I have it and asked if I wanted to repair.
https://learn.microsoft.com/en-us/cpp/windows/latest-supported-vc-redist?view=msvc-170
I have Norton Antivirus, I made sure to set Ubot Studio to allow internet access & unblocked it's activities.
Any idea on how to fix this, I've put in a support ticket but have not heard back yet.
Any help is greatly appreciate.
thank you